Azure Data Lake Solution Architecture
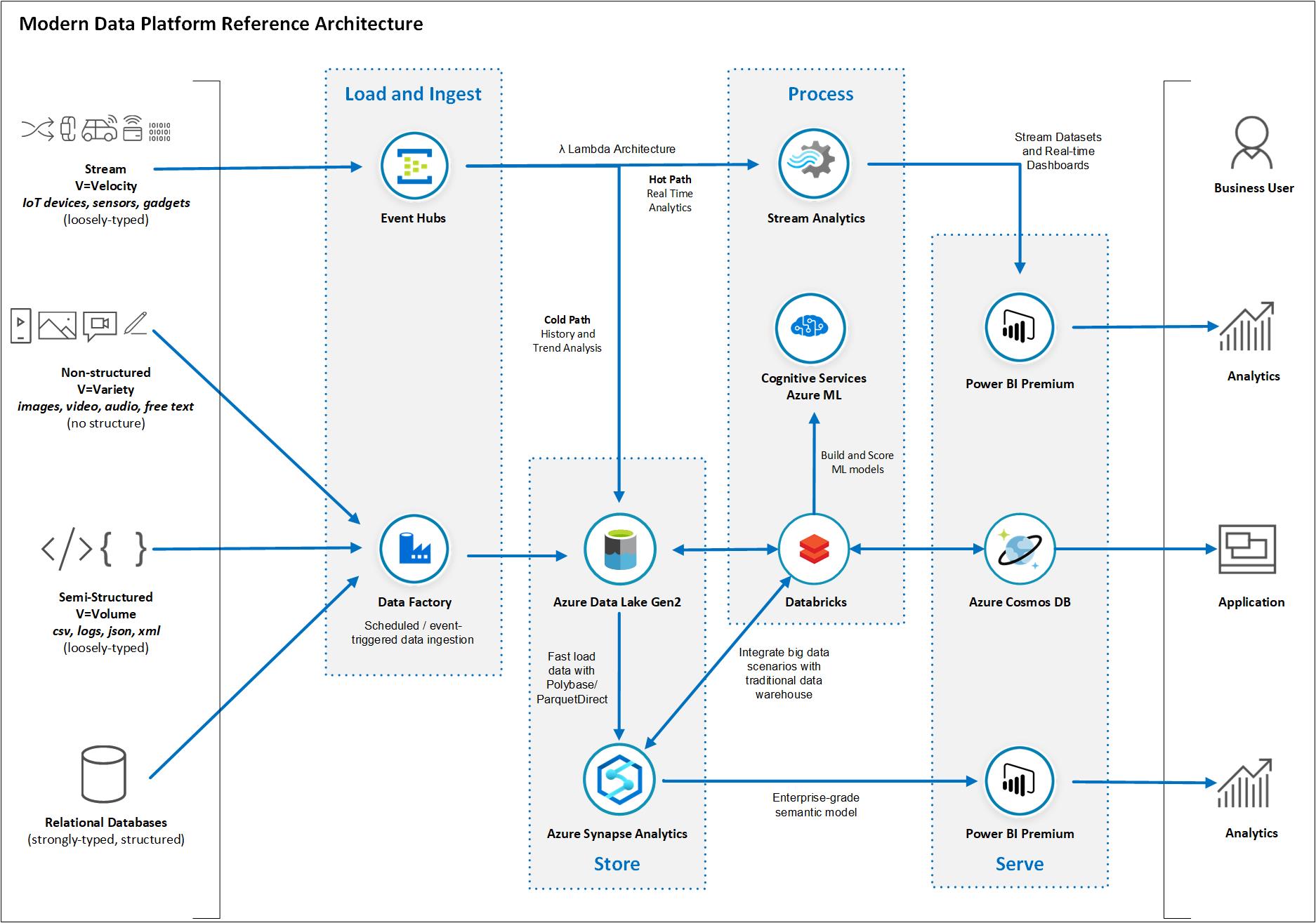
Azure Data Platform End To End Azure Example Scenarios Microsoft Docs
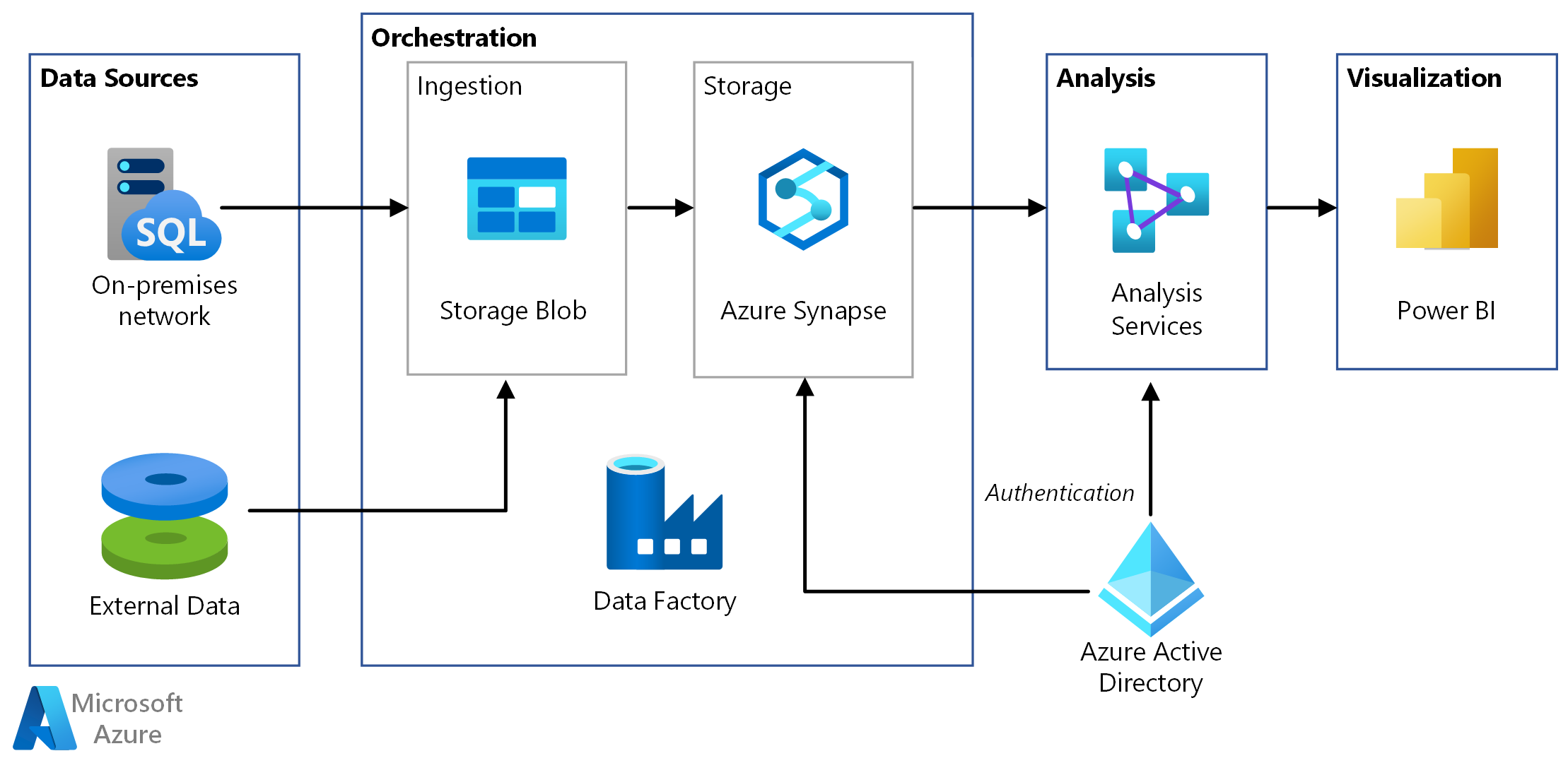
Automated Enterprise Bi Azure Architecture Center Microsoft Docs

Anaplan Drinks From Azure Data Lake Anaplan Community

The Common Data Model In Azure Data Lake Storage Azure Data Services Adatis
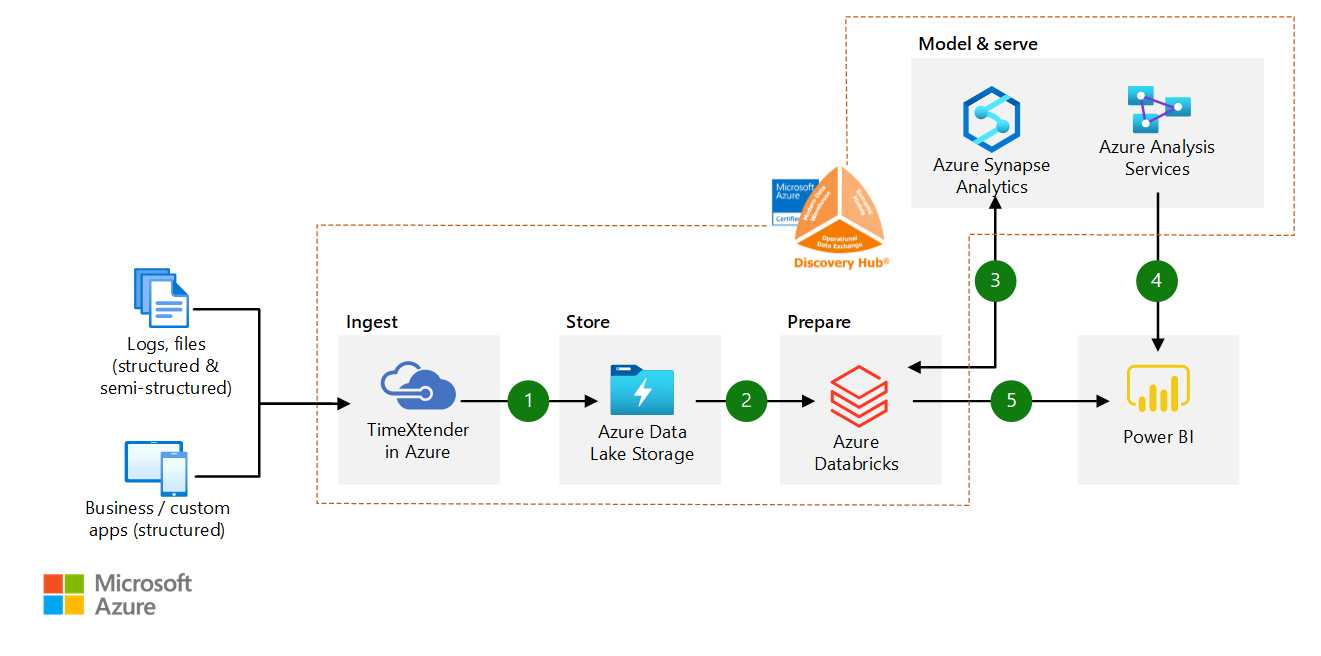
Discovery Hub With Cloud Scale Analytics Azure Solution Ideas Microsoft Docs

Azure Data Lake And Analytics Capabilities And Architecture Xenonstack

Because the data sets are so large often a big data solution must process data files using long running batch jobs to filter aggregate and otherwise prepare the data for analysis.
Azure data lake solution architecture.

Dba Consulting Blog Azure Data Architecture

Enterprise Azure Analytics Solutions Snowflake On Microsoft Azure
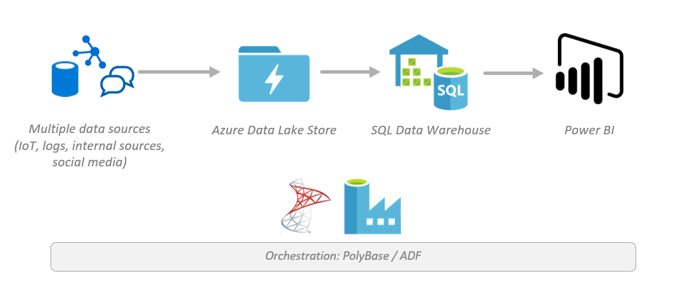
Azure Data Architecture Guide Blog 8 Data Warehousing Microsoft Tech Community 352865
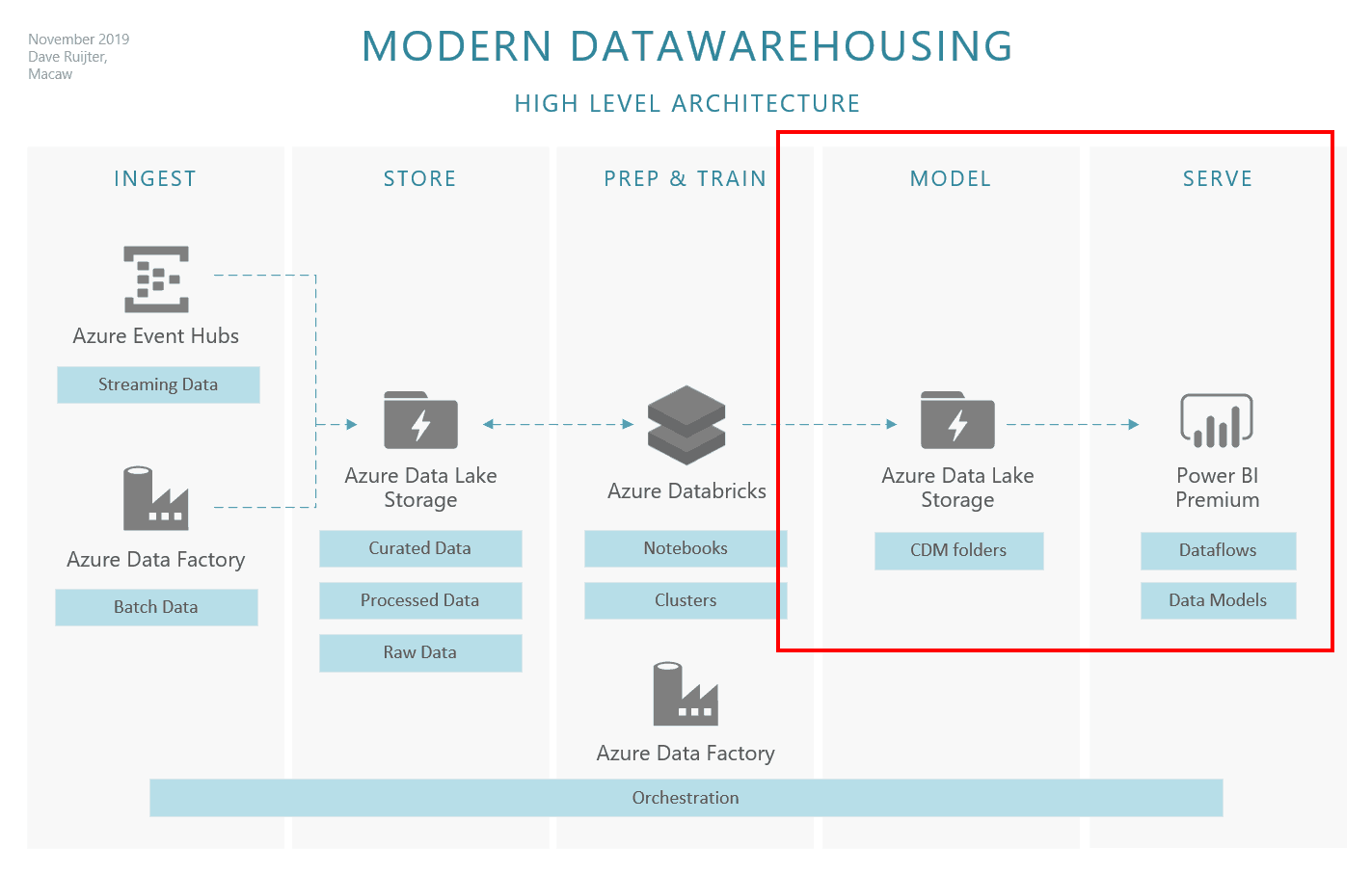
Mini Series Announcement Modern Datawarehousing Using Azure Data Lake Cdm Folders And Power Bi Dataflows Modern Data Ai

Azure Advanced Analytics For Non Microsoft Customers Visual Bi Solutions
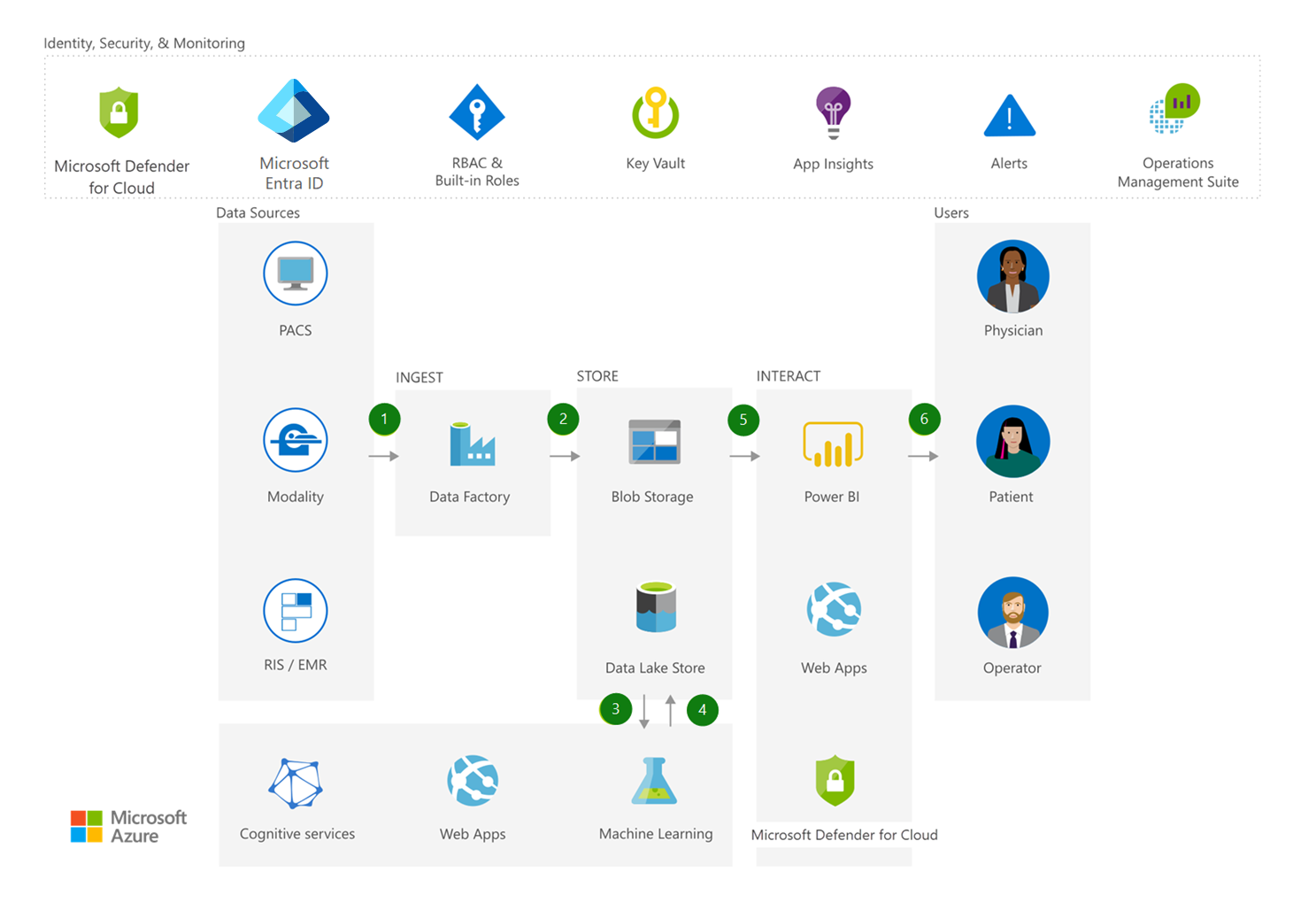
Medical Data Storage Solutions Azure Solution Ideas Microsoft Docs
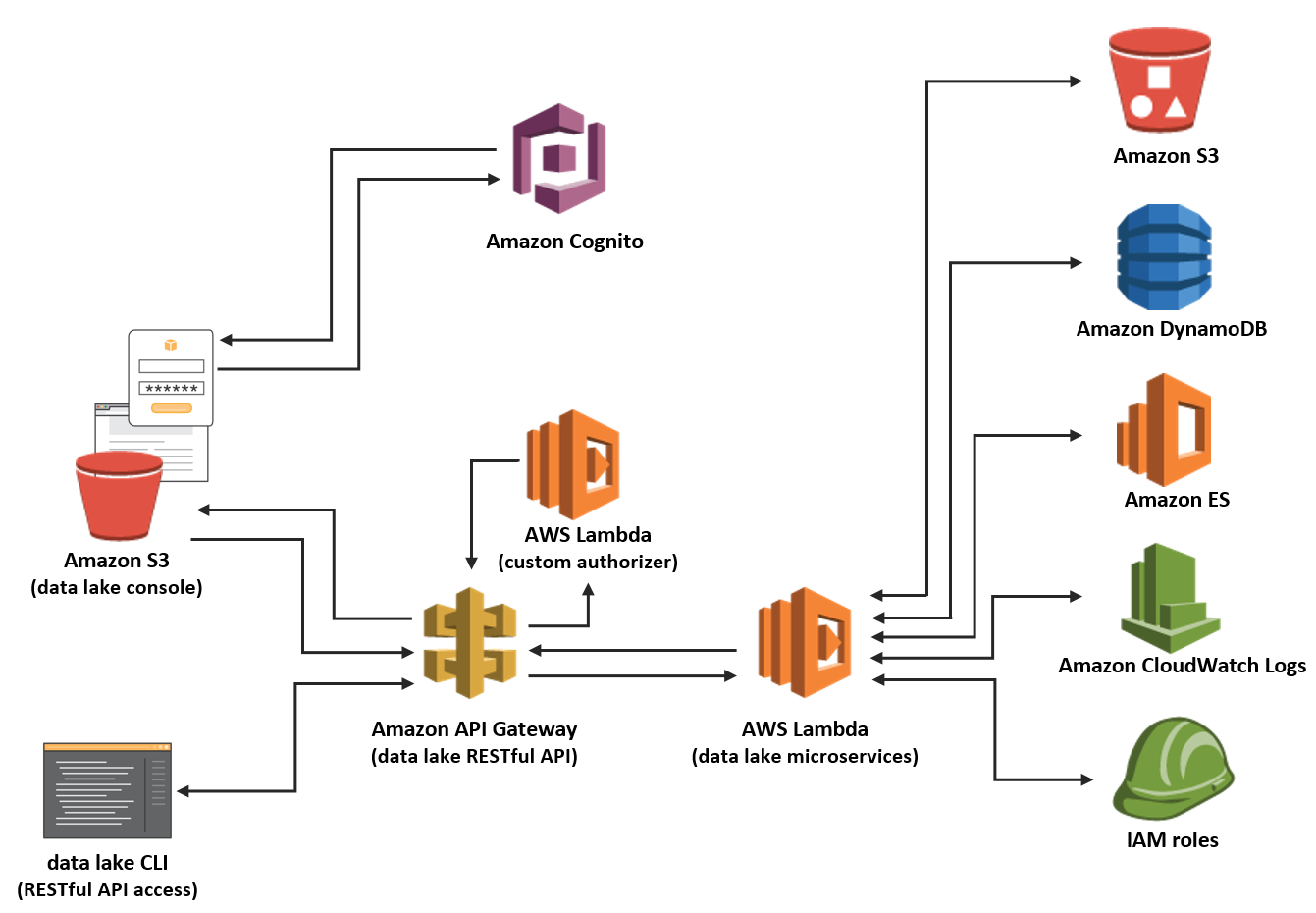
Data Lake Template For Azure Aws Solutions Demo

Use Cases Of Various Products For A Big Data Cloud Solution James Serra S Blog

Batch Processing Azure Architecture Center Microsoft Docs
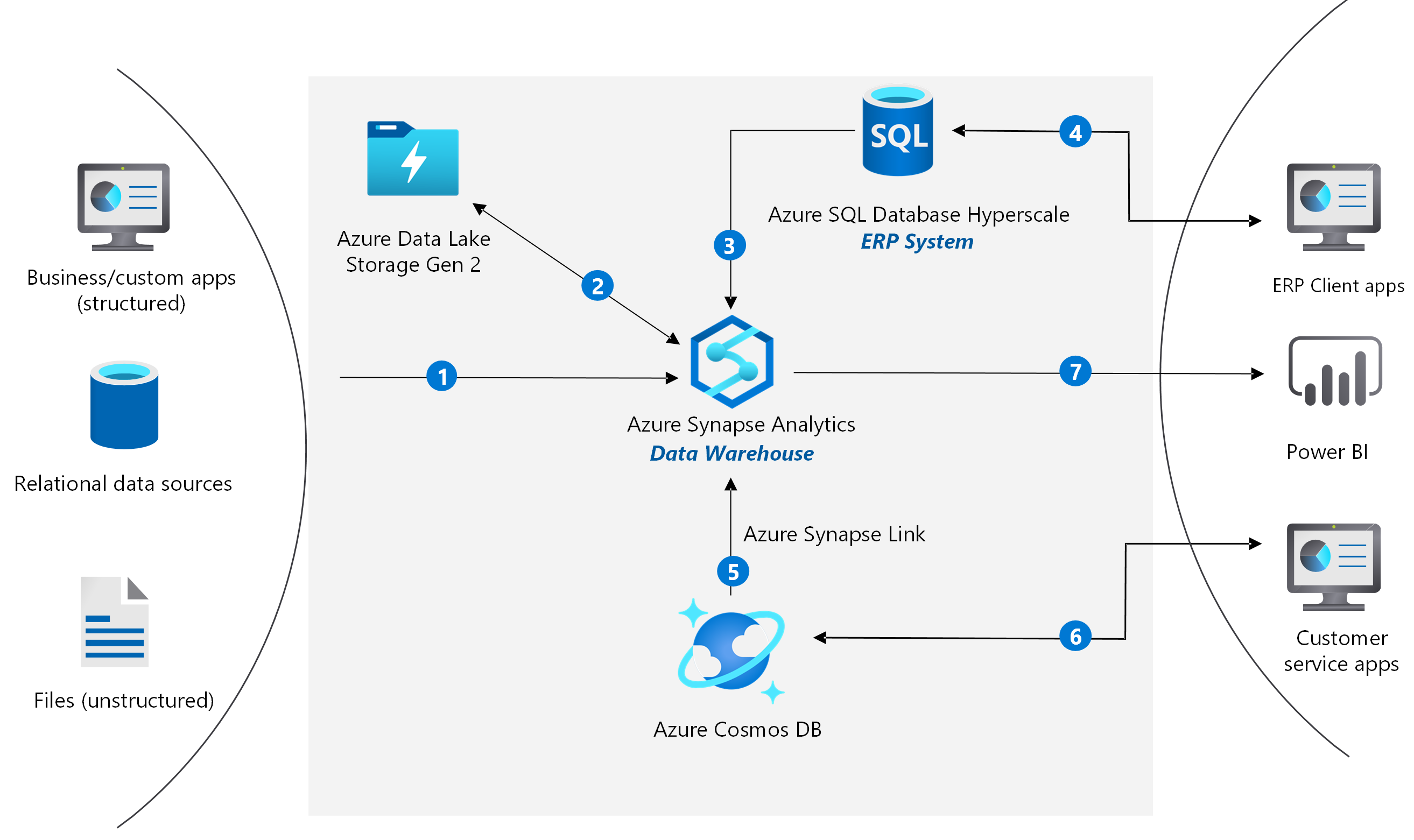
Deliver Highly Scalable Customer Service And Erp Apps Azure Solution Ideas Microsoft Docs
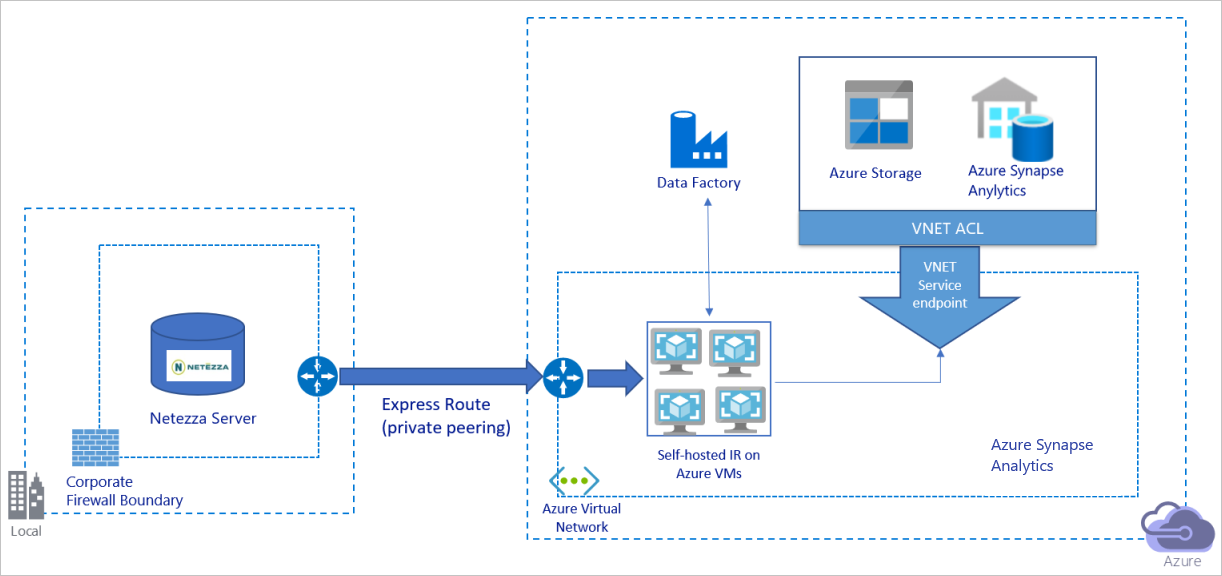
Migrate Data From An On Premises Netezza Server To Azure Azure Data Factory Microsoft Docs
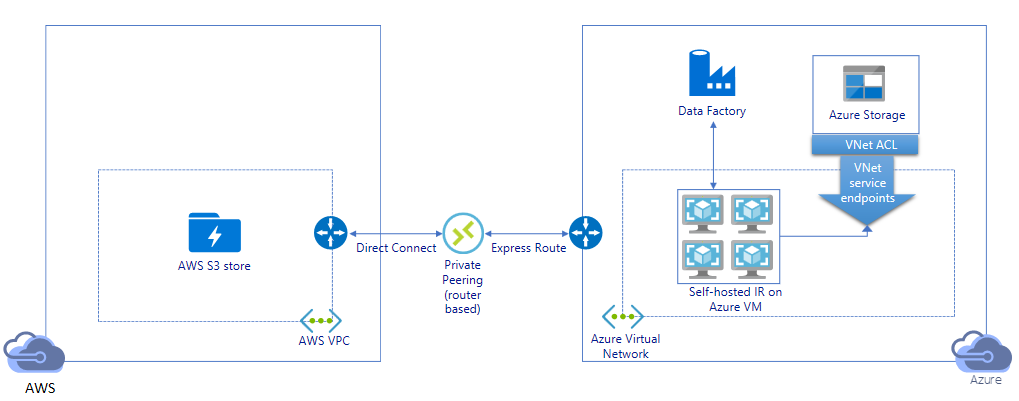
Migrate Data From Amazon S3 To Azure Storage Azure Data Factory Microsoft Docs
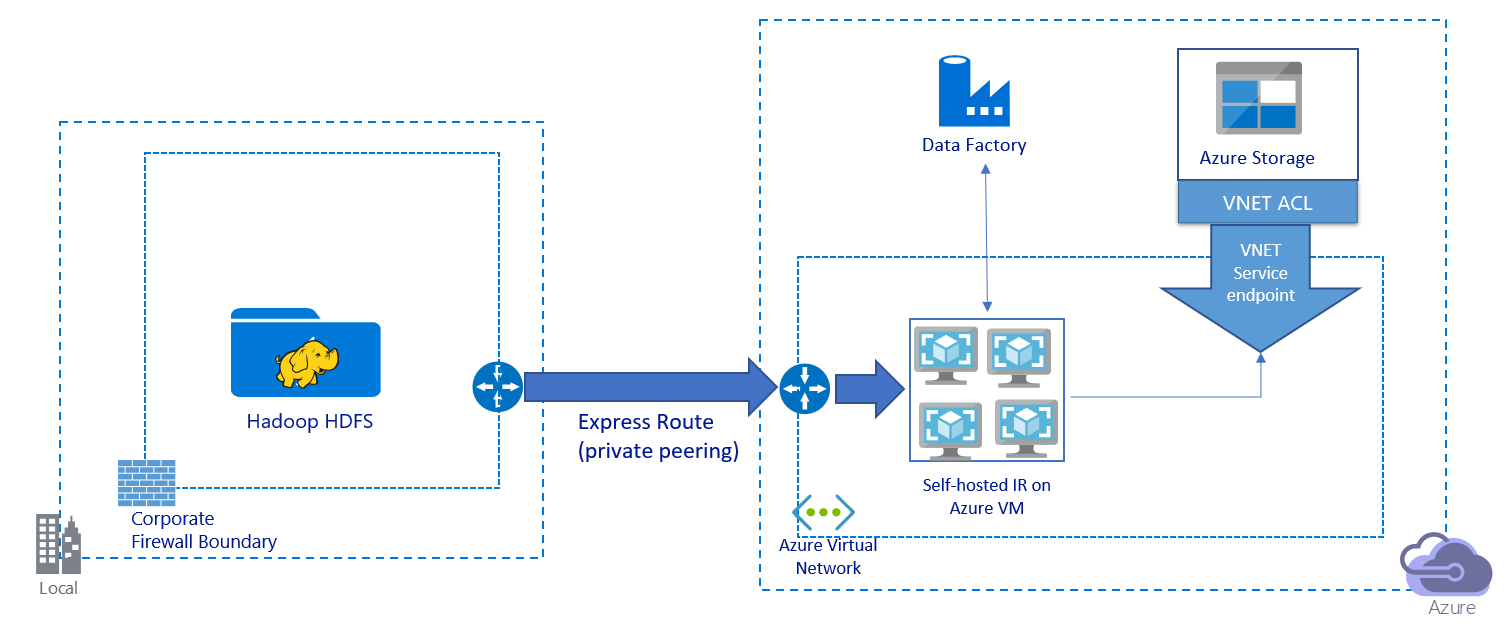
Migrate Data From An On Premises Hadoop Cluster To Azure Storage Azure Data Factory Microsoft Docs
Real Time Data Analytics And Azure Data Lake Storage Gen2 Data Analytics Real Time Big Data Analytics

Continuous Real Time Data Integration To Azure Data Lake Striim
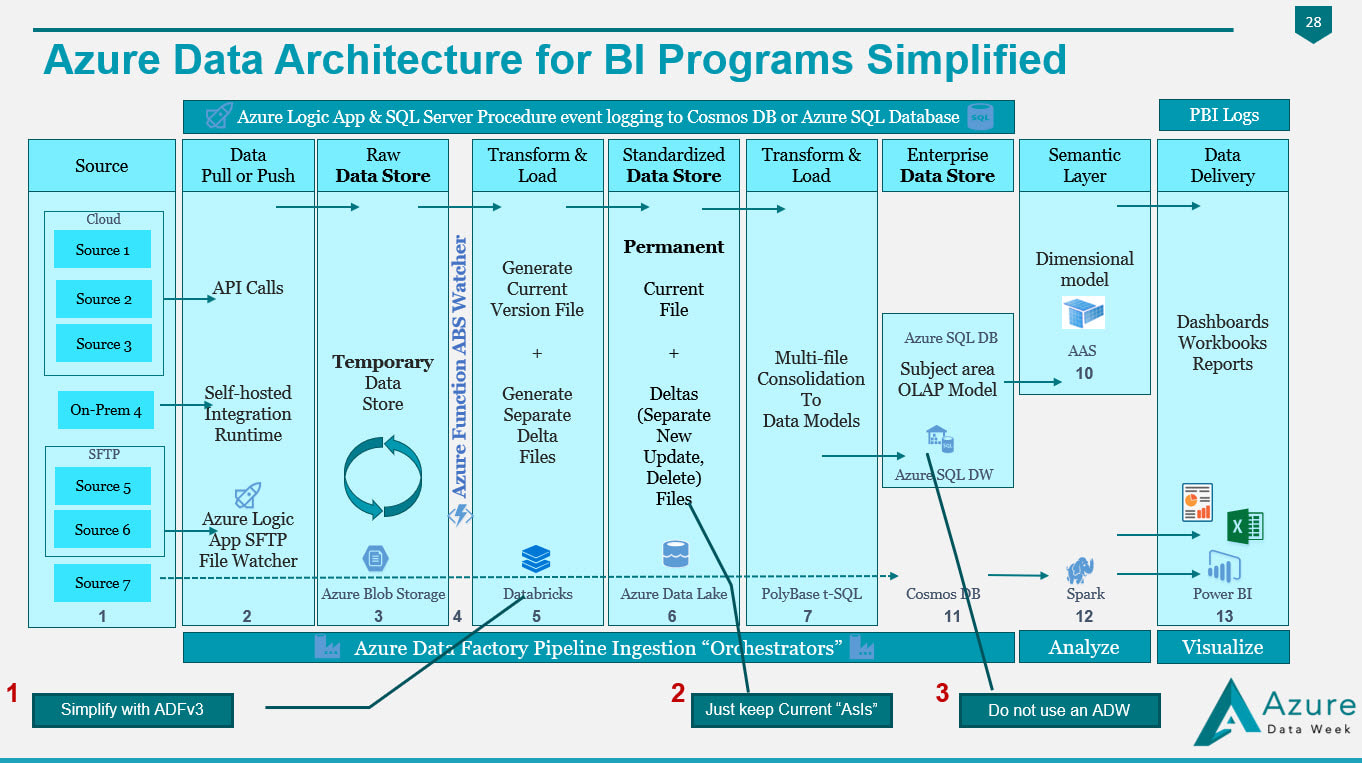
Transitioning From Traditional To Azure Data Architectures Ssis To Azure Data Factory Sql Database To Sql Data Warehouse Scheduled Extract To Event Based Extracts Microsoft Data Ai

Microsoft Business Intelligence Solutions Db Best

Microsoft Customer Story Xto Energy Taps Into Iot And The Cloud To Optimize Operations And Drive Growth With Azure And Dynamics 365
Https Encrypted Tbn0 Gstatic Com Images Q Tbn 3aand9gcrlvwv7pttuhsy3pcaxpxkh 4f7nhv2jugtfk7j12g Usqp Cau
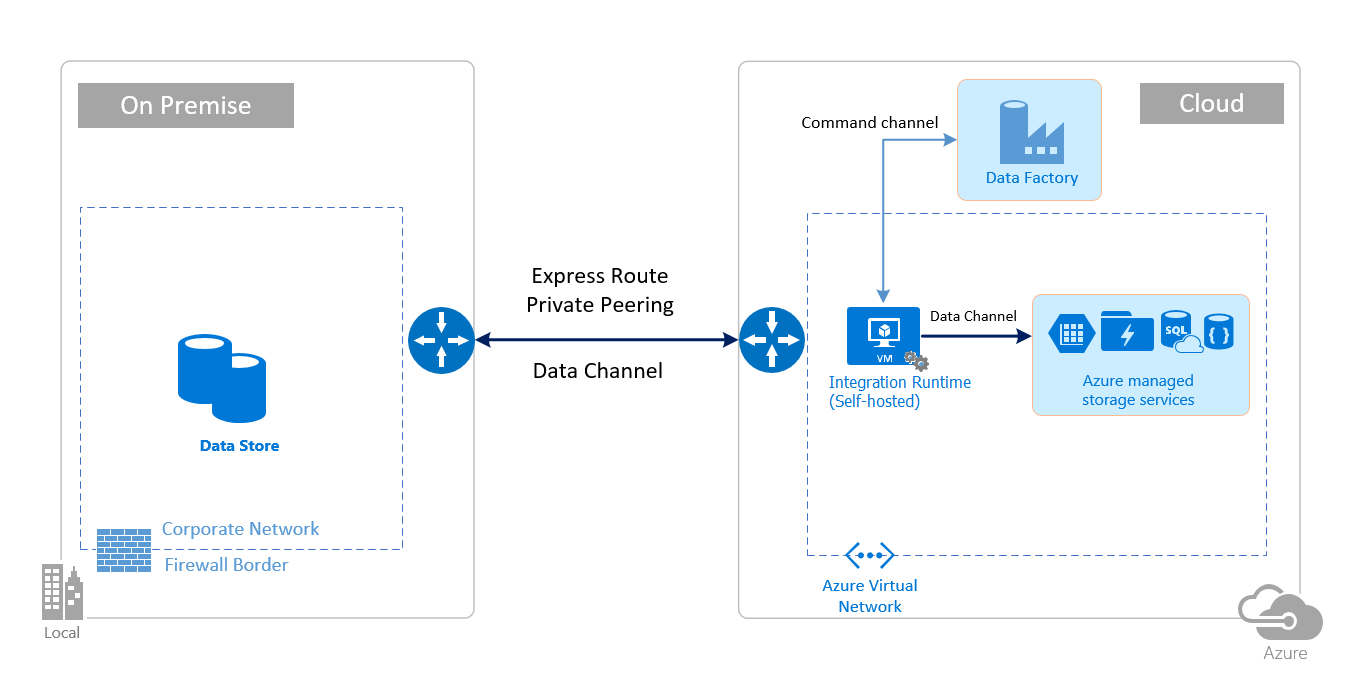
Security Considerations Azure Data Factory Microsoft Docs

The Emerging Big Data Architectural Pattern Ilikesql
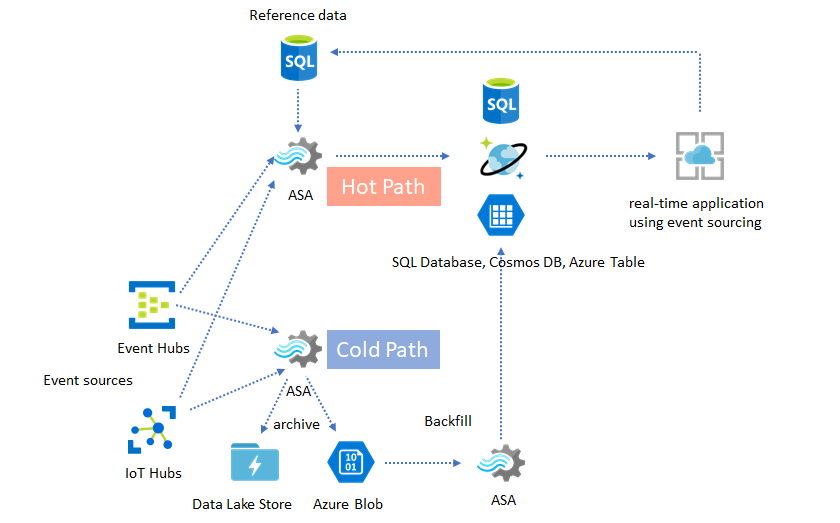
Azure Stream Analytics Solution Patterns Microsoft Docs
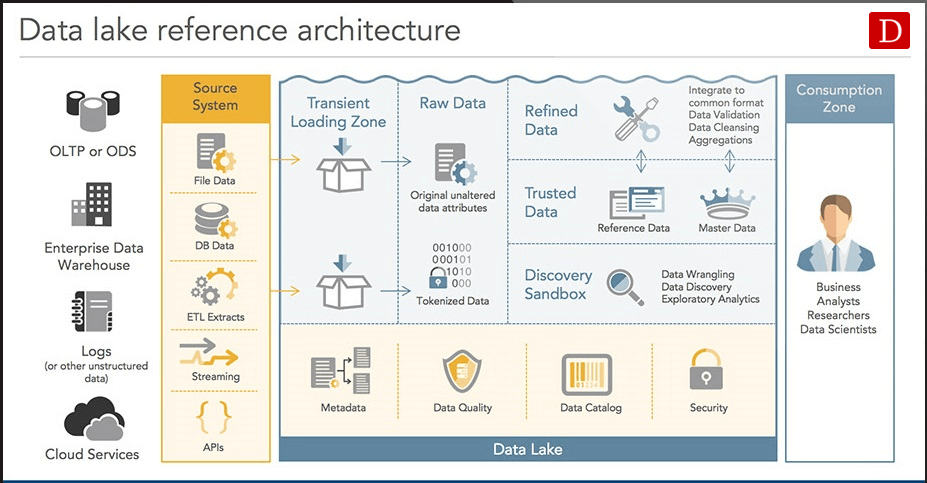
Data Lake Definition Dragon1
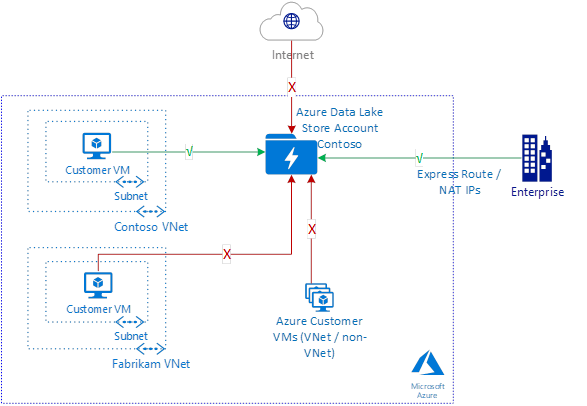
Network Security In Azure Data Lake Storage Gen1 Microsoft Docs
Source : pinterest.com
